Training Data on Chilean Congress Bills
Researchers: Carla Cisternas, Bastián González-Bustamante, Jaquelin Morillo and Diego Aguilar



Data and Samples
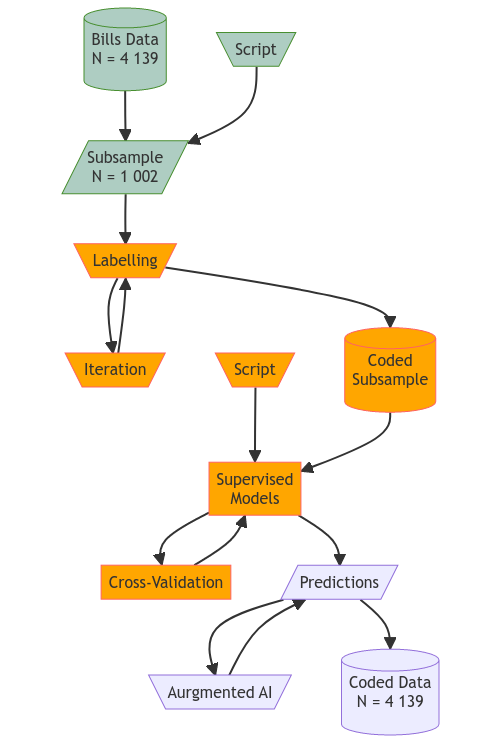
From a data set of bills in the Chilean Lower House between 2006 and 2018 (N = 4,139), a period that corresponds to three administrations, we draw a random subsample considering some bills per month. We are carrying out two data coding procedures in this subsample in order to identify both the bill’s issue and territorial scope.
Coding Chilean Congress Bills
We are looking for ad honorem coders to label our Congress bills’ subsample for this project. We need bachelor or master students of social sciences programmes. Our coders will receive general training and dedicate a variable and flexible amount of time to this task.
We do not work with a specific number of coders because we iterate the labelling process to shape up coding accuracy until achieving a high-reliability level. Each subsample observation requires validation of a different number of coders depending on the specific classification task categories. For example, identifying the territorial scope has a higher threshold of coders than codifying the bills’ issue, which has less possible outcomes.
For further details, please contact c.g.cisternas.guasch@hum.leidenuniv.nl.
Machine Learning Classification
Once the database is codified, we train a model and predict the non-coded data using machine learning techniques. At this stage, it is possible to incorporate human validation in the workflow to validate observations with low confidence values. Finally, we will have the data necessary to carry out our principal analysis, in this case, stochastic actor-based models for networks dynamics, to observe co-sponsorship strategies in the Chilean Congress over the period.
Progress
| 1. Data Gathering |  |
2. Data Cleaning | |
|||
| 3. Labelling |  |
4. Labelling Iterations |  |
|||
| 5. Train Model |  |
6. Evaluate Model | |
|||
| 7. Predictions |  |
8. Augmented AI | |
Artwork by DALL·E in an Impressionist style.
Diagram by Cisternas, González-Bustamante, Morillo and Aguilar (2021).
Last updated: March 18, 2023.