Training Data on Political Science Publications
Researchers: Bastián González-Bustamante, Alejandro Olivares and Carla Cisternas

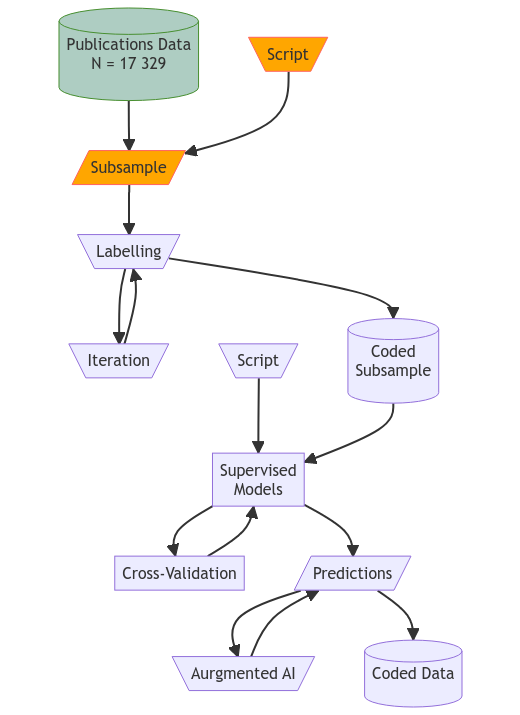
Data and Samples
Based on data from the the Chilean Politics Science Impact Ranking (CPS-Ranking), we have collected all the authors’ publications ranked in the first quartile (Q1) according to his/her H-Index. From this data set, we exclude publications in English and draw a random subsample. We are carrying out data coding procedures in this subsample to classify the type of publication using a typology of political science’s subfields.
Coding Political Science Publications
For the moment, we are not looking for coders to label our political science publications subsample in this project. Considering the complexity of this task due to the level of knowledge necessary, we are working with a small group of coders with a high level of expertise. Nevertheless, we would appreciate any interest in this project because we could need eventually support during the augmented artificial intelligence phase.
For further details, please contact bastian.gonzalezbustamante@politics.ox.ac.uk.
Machine Learning Classification
Once the subsample is codified, we train a model a predict the non-coded data using machine learning techniques. At this stage, we could eventually incorporate external human validation to revise the low predicted values. Finally, we will have the data to carry out predictions on new data about political science production in Latin America.
Progress
| 1. Data Gathering |  |
2. Data Cleaning | |
|||
| 3. Labelling |  |
4. Labelling Iterations | |
|||
| 5. Train Model | |
6. Evaluate Model | |
|||
| 7. Predictions | |
8. Augmented AI | |
Artwork by DALL·E in an Impressionist style.
Diagram by González-Bustamante, Olivares and Cisternas (2021).
Last updated: October 15, 2021.